Concepts¶
The Concepts section digs deeper into parts of the FactoryTX system and helps you obtain a better understanding of how FactoryTX works.
Overview¶
The Sight Machine platform offers a suite of services from acquiring factory data to modeling, analyzing, and visualizing it. FactoryTX starts the process; it is the component for data acquisition. FactoryTX Edge directly collects data from machines in the factory, while FactoryTX Cloud collects machine data from a cloud database. The collected data is then uploaded to the Sight Machine cloud and made available for the AI Data Pipeline to contextualize and model and for the Manufacturing Application (MA) Suite to visualize and analyze.
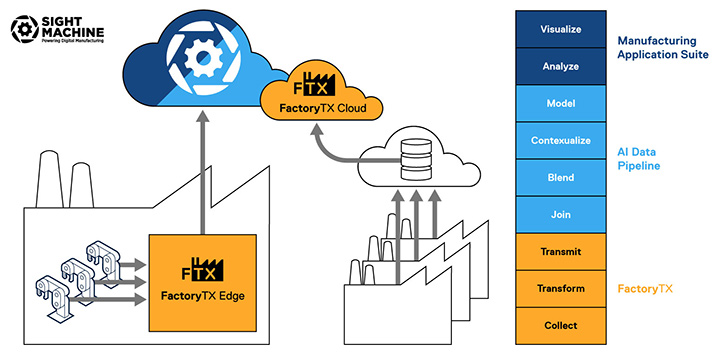
Within FactoryTX, there are three main steps:
COLLECT: gather production data from cloud or factory data source(s) (e.g. OPC-UA servers, SQL databases)
TRANSFORM: condition and format the data
TRANSMIT: compress, encrypt, and upload the conditioned data to the Sight Machine cloud for storage and use by other Sight Machine services (e.g. AI Data Pipeline)
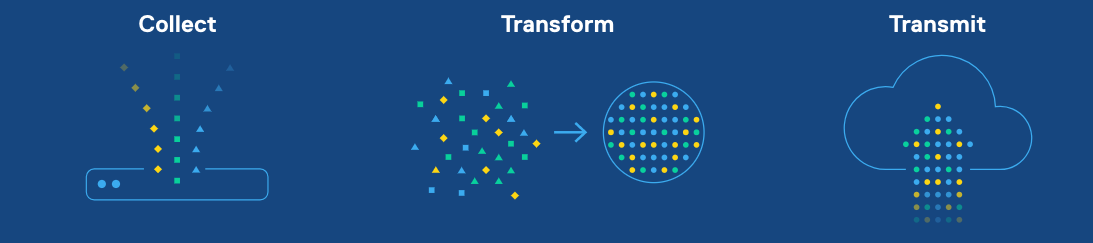
Receivers and Transforms and Transmits¶
Each step in the FactoryTX data pipeline is handled by a type of component. A receiver collects production data from a source such as a CSV file and SQL table. A transform applies some kind of transformation to the data like adding a time zone to a timestamp. A transmit transfers the data to another location (e.g. Sight Machine cloud).
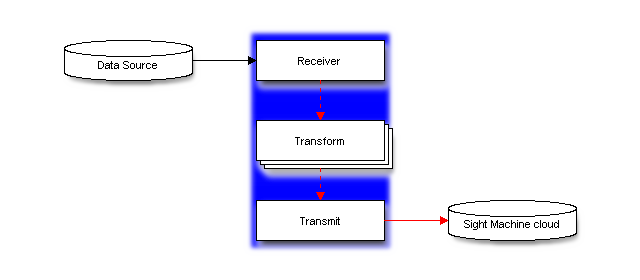
The sections of a FactoryTX configuration file correlate to each step in the data pipeline, so we can clearly define which component(s) of each type are needed.
data_receiver: receive datatransforms: transform datadata_transmit: transmit dataSM Cloud Credentials: transmit data
Using the sample configuration from the Quickstart guide for context, let’s take a deeper look at what’s configured in each section.
data_receiver
The data_receiver section is a list of configurations for receiver
components. A receiver configuration describes how it connects to a data source,
how it reads the data, and how the data is passed through the rest of the
FactoryTX data pipeline.
1 "connections": [
2 {
3 "database_type": "mssql",
4 "host": "35.233.132.166",
5 "port": 1433,
6 "username": "rexy",
7 "password": "islaNublar93",
8 "database_name": "Demo",
9 "ssl": false,
10 "connection_name": "Nedry"
11 }
12 ],
13 "streams": [
14 {
15 "asset": "lasercut",
16 "stream_type": "mssql",
17 "state_fields": [
18 {
19 "column_name": "timestamp",
20 "data_type": "timestamp",
21 "initial_value": "2018-10-22 10:29:00"
22 }
23 ],
24 "query": "SELECT * FROM ca_lasercut\nWHERE timestamp > :timestamp\nORDER BY timestamp;"
25 },
26 {
27 "asset": "diecast",
28 "stream_type": "mssql",
29 "state_fields": [
30 {
31 "column_name": "TIMESTAMP",
32 "data_type": "timestamp",
33 "initial_value": "2018-10-22 12:29:00"
34 }
35 ],
36 "query": "SELECT * FROM hk_diecast\nWHERE TIMESTAMP > :TIMESTAMP\nORDER BY TIMESTAMP;"
37 },
38 {
39 "asset": "fusion",
40 "stream_type": "mssql",
41 "state_fields": [
42 {
43 "column_name": "timestamp",
44 "data_type": "timestamp",
45 "initial_value": "2018-10-22 02:28:00"
46 }
47 ],
48 "query": "SELECT * FROM tl_fusion WHERE timestamp > :timestamp ORDER BY timestamp;"
49 }
50 ]
51 },
52 {
53 "data_receiver_name": "azure_receiver_1",
54 "protocol": "azure_data_lake",
55 "poll_interval": 5,
56 "connections": [
57 {
58 "tenant_id": "beb1d7f9-8e2e-4dc4-83be-190ebceb70ea",
59 "client_id": "b8d454e3-67ec-4f2f-8dcb-a5d6f87abbc6",
60 "client_secret": "BdgGBpZ7pS.Ogf..7PpT0JVLXes.i1uh",
61 "store_name": "factorytxreceivertest",
62 "data_directory": "directory-1",
63 "max_files_per_request": 1,
64 "connection_name": "Blue"
65 }
66 ],
67 "parsers": [
68 {
69 "parser_name": "CSV_Parser_1",
70 "parser_type": "csv"
71 }
72 ],
73 "streams": [
74 {
75 "asset": "spraypaint",
76 "stream_type": "azure_lake",
77 "file_filter": [
78 "*.csv"
79 ],
80 "parser": "CSV_Parser_1"
81 }
82 ]
83 }
84 ],
85 "transforms": [
86 {
87 "transform_name": "Rename 1",
Each receiver uses a protocol to connect to a data source. For example, the
SQL Plugin 1 receiver connects to our remote MS SQL Server with a database
that holds all of the machine data for our Carmel, Hong Kong, and Toulouse
factories.
1 {
2 "database_type": "mssql",
3 "host": "35.233.132.166",
4 "port": 1433,
5 "username": "rexy",
6 "password": "islaNublar93",
7 "database_name": "Demo",
8 "ssl": false,
9 "connection_name": "Nedry"
10 }
11 ],
12 "streams": [
13 {
14 "asset": "lasercut",
15 "stream_type": "mssql",
16 "state_fields": [
17 {
18 "column_name": "timestamp",
19 "data_type": "timestamp",
20 "initial_value": "2018-10-22 10:29:00"
21 }
22 ],
23 "query": "SELECT * FROM ca_lasercut\nWHERE timestamp > :timestamp\nORDER BY timestamp;"
24 },
25 {
26 "asset": "diecast",
27 "stream_type": "mssql",
28 "state_fields": [
29 {
30 "column_name": "TIMESTAMP",
31 "data_type": "timestamp",
32 "initial_value": "2018-10-22 12:29:00"
33 }
34 ],
35 "query": "SELECT * FROM hk_diecast\nWHERE TIMESTAMP > :TIMESTAMP\nORDER BY TIMESTAMP;"
36 },
37 {
38 "asset": "fusion",
39 "stream_type": "mssql",
40 "state_fields": [
41 {
42 "column_name": "timestamp",
43 "data_type": "timestamp",
44 "initial_value": "2018-10-22 02:28:00"
45 }
46 ],
47 "query": "SELECT * FROM tl_fusion WHERE timestamp > :timestamp ORDER BY timestamp;"
48 }
49 ]
50 },
51 {
52 "data_receiver_name": "azure_receiver_1",
53 "protocol": "azure_data_lake",
54 "poll_interval": 5,
The streams section defines how to read from the SQL table and how the data
will flow through the pipeline. Each factory’s data is stored in a separate
table in the database. Since we want to keep this order, we configure three
streams. Each stream uses a SQL query to control what is read into FactoryTX and
the asset and stream_type keys are data labels that will be used by
other FactoryTX components as well as other Sight Machine services.
The azure_receiver_1 receiver connects to our Azure Data Lake instance that
contains data about our spray-paint machines in Tokyo, Japan.
1 "connections": [
2 {
3 "tenant_id": "beb1d7f9-8e2e-4dc4-83be-190ebceb70ea",
4 "client_id": "b8d454e3-67ec-4f2f-8dcb-a5d6f87abbc6",
5 "client_secret": "BdgGBpZ7pS.Ogf..7PpT0JVLXes.i1uh",
6 "store_name": "factorytxreceivertest",
7 "data_directory": "directory-1",
8 "max_files_per_request": 1,
9 "connection_name": "Blue"
10 }
11 ],
12 "parsers": [
13 {
14 "parser_name": "CSV_Parser_1",
15 "parser_type": "csv"
16 }
17 ],
18 "streams": [
19 {
20 "asset": "spraypaint",
21 "stream_type": "azure_lake",
22 "file_filter": [
23 "*.csv"
24 ],
25 "parser": "CSV_Parser_1"
26 }
27 ]
28 }
29 ],
30 "transforms": [
31 {
Since the data is stored as CSV files in Azure, the stream will look for CSV files and use a file parser component to translate the file contents into digestible data for FactoryTX.
We’ll talk more about how data flows through the FactoryTX pipeline in a later section: Data streams. Details about data_receiver configurations and Parsers Configurations can be found in the Configuration Reference.
transforms
The transforms section contains a list of transform components that can be
applied to specific data streams.
1 "transform_type": "rename",
2 "filter_stream": [
3 "diecast:mssql"
4 ],
5 "renames": [
6 {
7 "from": "TIMESTAMP",
8 "to": "timestamp"
9 }
10 ]
11 },
12 {
13 "transform_name": "Rename 2",
14 "transform_type": "rename",
15 "filter_stream": [
16 "spraypaint:azure_lake"
17 ],
18 "renames": [
19 {
20 "from": "Timestamp",
21 "to": "timestamp"
22 }
23 ]
24 },
25 {
26 "transform_name": "Time Converter 1",
27 "transform_type": "convert_timestamps",
28 "filter_stream": [
29 "spraypaint:*"
30 ],
31 "field_names": [
32 "timestamp"
33 ],
34 "timezone": "Asia/Tokyo"
35 },
36 {
37 "transform_name": "Time Converter 2",
38 "transform_type": "convert_timestamps",
39 "filter_stream": [
40 "lasercut:mssql"
41 ],
42 "field_names": [
43 "timestamp"
44 ],
45 "timezone": "America/New_York"
46 },
47 {
48 "transform_name": "Time Converter 3",
49 "transform_type": "convert_timestamps",
50 "filter_stream": [
51 "diecast:mssql"
52 ],
53 "field_names": [
54 "timestamp"
55 ],
56 "timezone": "Asia/Hong_Kong"
57 },
58 {
59 "transform_name": "Time Converter 4",
60 "transform_type": "convert_timestamps",
61 "filter_stream": [
62 "fusion:mssql"
63 ],
64 "field_names": [
65 "timestamp"
66 ],
67 "timezone": "Europe/Paris"
68 }
69 ],
70 "data_transmit": [
71 {
72 "transmit_name": "MyTransmit_1",
A transform component can have a variety of settings to dictate which data to
transform and how to modify it. For example, we have two types of transforms:
convert_timestamps and rename. As implied by their type, a
convert_timestamp transform will convert a timestamp into a specified time
zone, and a rename transform will rename the title of a data field.
The order of the transform components in the list correlate to the order in
which they are evaluated. In the case of the Quickstart configuration,
Rename 1 is evaluated first, followed by Rename 2, and ultimately
Time Converter 4. This order of operations allows us to reuse transform
components for various data sources.
Details about Transforms configurations can be found in the Configuration Reference.
SM Cloud Credentials and data_transmit
The SM Cloud Credentials and data_transmit sections work together to
define how and to where a transmit component transfers the data.
1 "data_receiver": [
2 {
3 "data_receiver_name": "SQL Plugin 1",
4 "protocol": "sql",
5 "poll_interval": 10,
6 "transmit_type": "remotedatapost"
7 }
8 ]
9}
In the example configuration, the transmit component is passing data from FactoryTX to a Sight Machine cloud instance for other Sight Machine services to ingest.
Details about SM Cloud Credentials and Transmit configurations can be found in the Configuration Reference.
What is a record?¶
When a receiver component collects production data from a source, each data point is converted into a record. A record represents the state of an asset at a specific point in time. An asset is a label that describes which factory asset generated the data point.
For example, in the Quickstart configuration, we collect data from
various types of machines: laser cutting, die casting, fusing, and spray
painting. It’d be hard for the transform components to determine which data to
modify and which to ignore, so we assign the machine’s type (e.g. “lasercut”) as
the record’s asset value. In effect, we can specify which transforms apply
to a record.
Each record holds arbitrary data about the asset as a set of named columns,
where each column contains exactly one value. For instance, a LASERVOLTAGE
column for a laser cutting machine might hold the laser’s voltage, while a
PRODUCTSKU column might specify the SKU of the mold that’s currently being
created.
In addition to an asset and timestamp, each record also specifies a stream type.
The stream type is used to distinguish between data sources for the same asset.
In the Quickstart configuration, we use the data source type as the
record’s stream_type value: mssql for data from MS SQL server and
azure_lake for data from Azure Data Lake. However, if we received
environmental data for the laser cutting machines from another MS SQL server
instance, we might want to change the stream_type to be where the
measurement was taken (e.g. “lab_environment”).
An example of a record that FactoryTX could collect from a laser cutting machine:
timestamp asset stream_type LASERVOLTAGE PRODUCTSKU
2018-10-29 13:29:00 lasercut mssql 40.1753828873 jp_wrangler_staff_12
Records can have a variety of columns, depending on the data fields; however, there are a few special columns to pay attention to.
Required |
Special |
|---|---|
asset |
attachment_content_type |
stream_type |
attachment_filename |
timestamp |
attachment_path |
For more technical information about the attachment columns, please refer to the Attachment Parser.
Records flow through FactoryTX from receiver components to transform components and finally to the transmit component, which packages them up and transfers them for other systems and services to use. Generally, the destination of a transmit is a Sight Machine cloud environment.
Data streams¶
FactoryTX can collect data from multiple sources. As receivers convert data into
records, an asset and stream type are assigned to each record. We call the flow
of records through FactoryTX components a data stream. Because records are
sorted into data streams based on their asset and stream type, data streams are
identified and tracked with asset:stream_type syntax. For example, in our
Quickstart configuration, we collect laser cutting machine data from a
remote MS SQL server. The records have an asset value of lasercut and
a stream_type value of mssql, so the data stream is named
lasercut:mssql.
Because receivers can set the asset and stream type values of a record, we can
aggregate data from different sources into the same data stream. If there were
multiple MS SQL servers with laser cutting machine data, the SQL receiver could
join all the records into the same lasercut:mssql stream. Additionally, if
there was MS SQL backup data stored as CSV files on the local FactoryTX instance,
the file receiver component could parse the data and apply the same asset and
stream type values as the SQL receiver, so the records flow into the
lasercut:mssql stream.
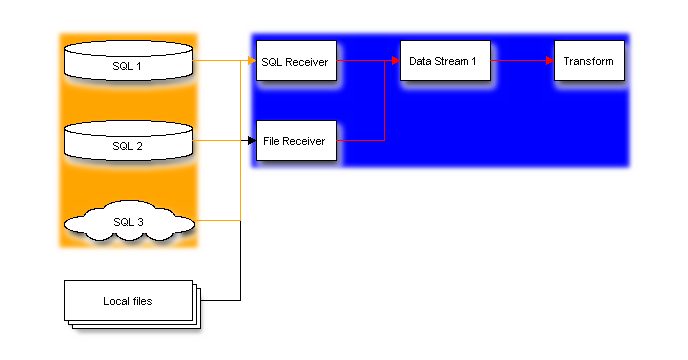
The order of the transform components defined in the configuration file is the
order in which they are evaluated. As data streams from receivers to
transforms, the first transform component in the list checks for streams that it
should modify. Every transform has a filter_stream property, which is a list
of stream names (e.g. lasercut:mssql) to look out for. When the name of a
data stream matches, the transform will modify the records of that data stream.
Data streams are checked by each transform in order as they flow through the
FactoryTX pipeline.
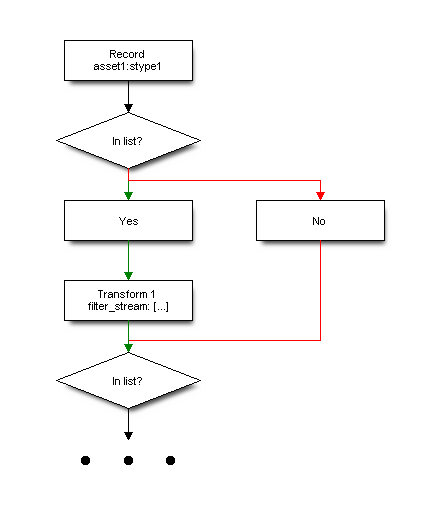
Additionally, transforms can dynamically generate or change a record’s asset and stream type. In effect, data streams may be created or joined together, so streams entering a transform may not match the streams exiting it. Because transforms are evaluated in order, the data streams that the next transform sees include any changed streams from the previous transform.
In the example configuration from the Quickstart guide, we collect data
about 6 different laser cutting machines using the MS SQL receiver. The receiver
places all of the records into the lasercut:mssql data stream for the
transforms to process. If we added a transform component that renames the
record’s asset based on the ID number of the laser cutting machine
(e.g. lasercut_1), new data streams would appear in the transform’s output
(e.g. lasercut_1:mssql). Subsequent transform components could then look for
a specific laser cutting machine’s data stream to modify, like rounding the
voltage value of lasercut_1 to the nearest hundredth to match the
precision of the measurement from the other laser cutting machines.
In FactoryTX, we refer to the data streams defined in the configuration file as input streams and the transmitted data streams as output streams.
Persistent state and restreaming¶
FactoryTX has state persistence, keeping track of what data has already been processed and transmitted. Restarting FactoryTX does not cause the system to re-process data and create duplicate records.
For example, in the configuration from the Quickstart guide, we collect die casting machine data from a table in a MS SQL database. The SQL receiver uses the timestamp value to keep track of which rows have been processed. As the die casting machines fill molds, rows (with newer timestamps) are added to the table, and the SQL receiver will fetch the new data for processing. If FactoryTX is paused while the die casting machines are working, when FactoryTX is restarted, it will continue fetching data from when it was paused.
Sometimes we want to fetch and process the same data again. The Streams UI has a table that tracks the state of input streams in the FactoryTX data pipeline. We can select specific data stream(s), or all of them, and use the restream option to clear the stream’s stored state. In effect, FactoryTX will collect and process all the data for the data stream again.

A caveat: make sure to remove old records from the Sight Machine platform before restreaming. Otherwise, there will be duplicate or overlapping records, causing other Sight Machine services to return bad output.
It should also be noted that if data is missing from the data source, there will be no way to restream it.
Process topology¶
FactoryTX runs one process per receiver, and one per RDPv2 transmit. This requires much less memory per stream, but still allows FactoryTX to use multiple CPU cores. To increase concurrency, you can duplicate a receiver configuration and divide up the streams.
Transforms are run as needed in the receiver process. This should still be relatively efficient, since most Pandas transforms require relatively little CPU compared to parsing; and we avoid the overhead of serializing Pandas DataFrames to pass them between processes.
Example of the process toplogy in action:
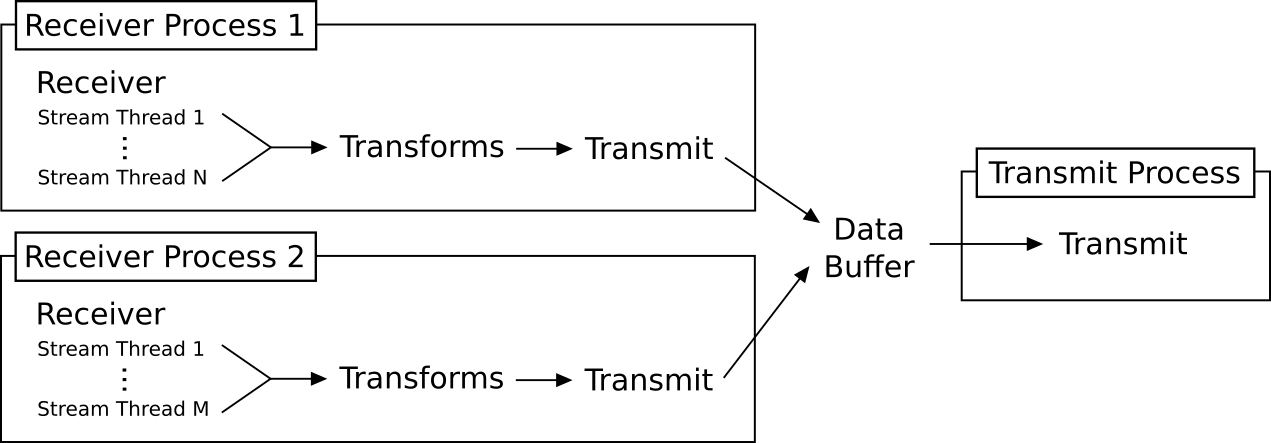
The “Transmit” in each receiver process decides how to handle data. In this example, RDPv2 transmit writes to a data buffer which a dedicated transmit process pulls from, but other transmits (e.g. a CSV transmit) might write directly to the destination and avoid running a separate process.